
Perplexity Cut Pro Deep Research to 20 a Month. My Hermes Agent Stack Runs Each Query for 22 Cents.
My research agent runs at $0.22 per deep query.
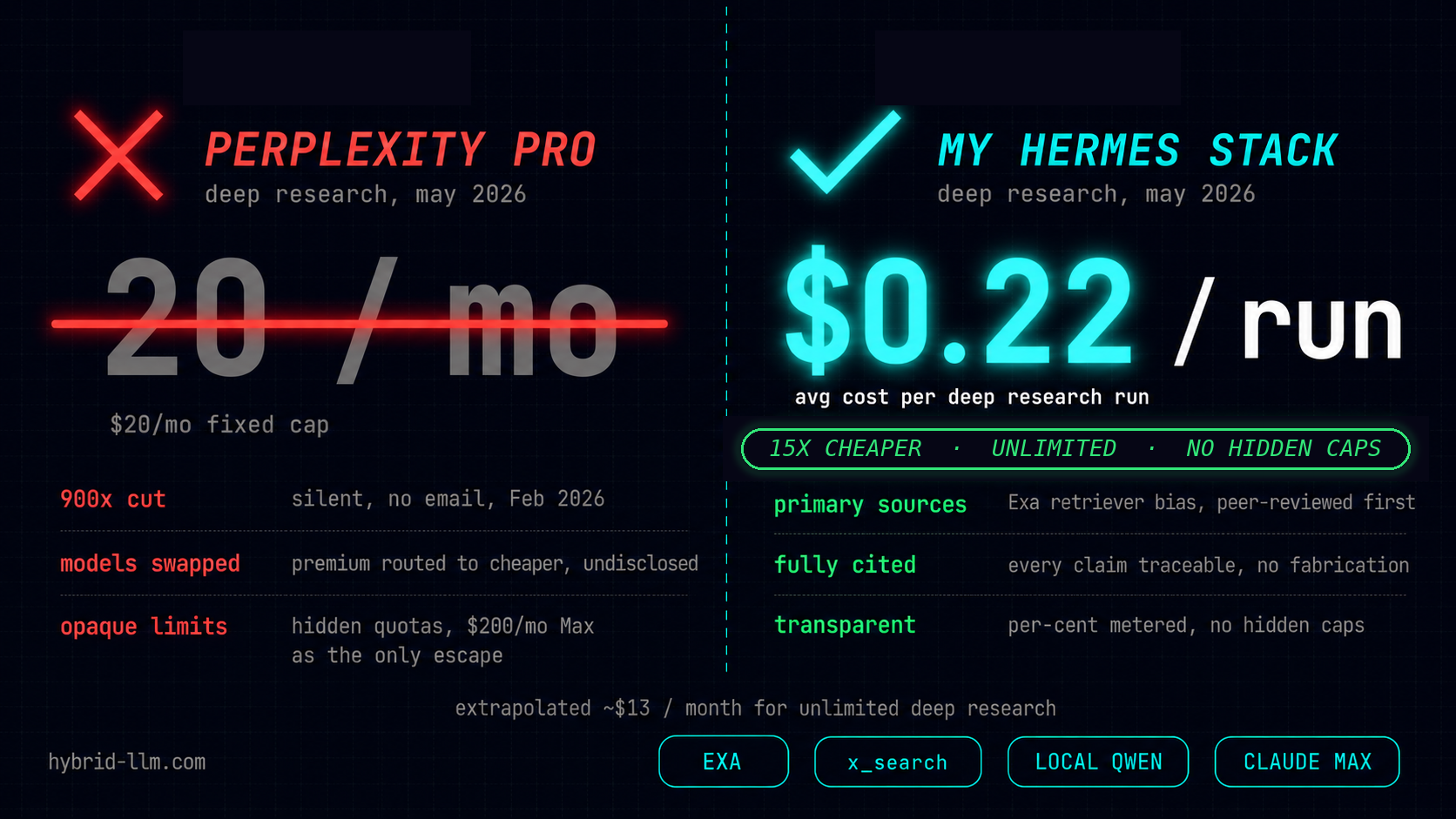
In February, Perplexity cut Pro Deep Research from roughly 600 queries a day to 20 a month. That is a 900x downgrade. They did it without notifying paying subscribers.
So I stopped using Perplexity for deep research and rebuilt the loop on Hermes Agent, Exa, x_search, one local model, and a Claude Max subscription I was already paying for.
Here is every cent of the 22, every component in the chain, and where Perplexity still wins.
The 900x downgrade
Perplexity Pro used to ship around 500 to 600 Deep Research queries per day, 50 Labs queries per month, and unlimited file uploads. That is the product I evaluated. I subscribed because the research mode was the closest thing to a credible Perplexity Max experience at one tenth the price.
Then in early February 2026, the changelog quietly said “usage limits have been adjusted to allocate more computing power per session.” In practice, Deep Research dropped to 20 queries per month for Pro. Some mobile users got four.
The Hacker News post that surfaced this was titled “900x downgrade of Perplexity Pro.” The math checks out. 600 daily times 30 days is 18,000 queries per month at the old rate. The new cap is 20. That ratio is 900.
No email went out. The web UI hid the new numbers. The phone app showed them only when you ran out. The recovery path was a $200 per month upgrade to Max.
That cut was my trigger. It took me a few months to replace the workflow, because the local stack required setup work and I kept hoping Perplexity would walk it back. By early May I had the loop running, and Perplexity Pro became a backup for one-shot lookups.
The 22-cent stack, line by line
Here is what each query costs.
| Layer | Tool | Per-run cost |
|---|---|---|
| Web search | Exa Search | $0.175 to $0.21 |
| X timeline signal | x_search via Hermes v0.14 | $0.015 to $0.025 |
| Local triage and embedding | Qwen3.6 + nomic-embed-text on llama-server | $0 |
| Synthesis | Claude Max subscription | $0 (amortized) |
| Orchestration | Hermes Agent + Claude Code | $0 (sunk) |
| Total per deep run | $0.19 to $0.235 |
A typical run hits Exa 25 to 30 times. Exa charges $7 per 1,000 requests with up to 10 results and content included, after their March 2026 pricing simplification. That is the heaviest line, and the only one that scales linearly with depth.
x_search is the xAI Agent Tools API exposed as a first-class Hermes tool in v0.14. Each call costs $0.005. I run three to five queries per research task to pull current X discourse on the topic. I wrote the full breakdown of x_search yesterday.
Qwen3.6 runs locally on my M2 Max through llama-server. Triage and embedding happen on hardware I already own. nomic-embed-text is open and free. The marginal cost of compute is electricity, which is real but trivial compared to the API spend.
Claude Max is a $200 per month subscription. I disclose this honestly because synthesis runs through Claude Code, which uses my Max plan. That makes the cost per individual research run zero on the synthesis side, but only if you already pay $200 a month for other Claude work. If you do not, factor that in. I do not amortize Max against the research loop because I would pay for Max either way.
I round this to 22 cents for budgeting. That is the number on the title.
Architecture
Four pieces, three APIs, one local model.
[Claude Code] -- orchestrator
|
|-- /deep-research --> [GPT Researcher v3.4.4]
| |-- LLM: Qwen3.6 (local llama-server)
| |-- Embeddings: nomic-embed-text (local)
| |-- Retriever: Exa Search
|
|-- [Hermes Agent] -- profile workflows
|-- x_search (xAI Agent Tools API)
|-- researcher / reviewer / analyst / writer / coder profiles
|-- local Qwen3.6 or cloud Kimi K2.6 per profile
|
|-- Synthesis pass (Claude Max via Claude Code)
|-- reads GPT Researcher output
|-- reads x_search results
|-- produces final deliverable
The flow is straightforward. I ask Claude Code a research question. It invokes GPT Researcher for deep web research. In parallel, I invoke a Hermes profile to run x_search for X timeline signal. Both outputs feed back into Claude Code, which writes the final synthesis.
GPT Researcher is the open-source autonomous deep research agent by Assaf Elovic, currently at v3.4.4 with 27,000 GitHub stars. It does recursive search, source validation, citation tracking, and report generation. The default config points at Tavily for retrieval. I switched to Exa in phase 2 because Exa’s primary-source bias and content extraction is better for the kinds of factual research I do (pricing, market structure, technical migrations).
Hermes Agent is the profile-based agent framework from Nous Research. v0.14 landed x_search as a first-class tool, which is the part that unlocks X timeline search inside the same agent loop. Before v0.14, getting current X data into a research run meant scrapers or the official X API at higher cost.
Setup
Three install commands. Twenty minutes if your disk is fast.
# 1. GPT Researcher
pip install gpt-researcher
# Configure .env with EXA_API_KEY and OPENAI_API_KEY pointing at local llama-server
# 2. Hermes Agent + x_search
pip install hermes-agent
hermes auth add xai --type api-key
hermes tools enable x_search
# 3. Local llama-server with Qwen3.6 (optional, if you do not already run one)
# Download Qwen3.6-27B Q5_K_M GGUF and run llama-server on :8080
The Exa free tier covers 1,000 requests per month, which is around 33 deep research runs at my call density. xAI typically issues promotional credits at signup; $20 on the account is roughly 4,000 x_search calls. Both let you validate the stack before any spend.
GPT Researcher’s config file lets you swap retrievers and LLMs independently. I keep my retriever set to Exa and my LLM pointed at the local llama-server. nomic-embed-text loads automatically as the embedding model when configured.
Scale math
The stack scales linearly. There is no monthly cap to bump into.
| Volume | Monthly cost |
|---|---|
| 1 deep run per day | $6.60 |
| 10 deep runs per day | $66 |
| 30 deep runs per day | $198 |
For comparison, Perplexity Pro at $20 per month gives you 20 Deep Research queries. At the cap, that works out to $1 per query. Perplexity Max at $200 per month is “unlimited” but with priority lanes that throttle in practice.
At 30 runs per day, the local stack reaches roughly the same monthly spend as Perplexity Max while delivering 900 runs against Max’s quota-limited “unlimited.” At 1 to 10 runs per day, where most independent builders operate, the local stack costs less than Perplexity Pro.
The scaling stays clean because each component is metered. No surprise tier bumps. No “rate limits have been adjusted.” If Exa changes pricing, I see it. If xAI deprecates an API, I see it. If my local hardware fails, I see it.
Where Perplexity still wins
I still open Perplexity Pro for three things.
Quick one-shot factual lookups where speed matters more than depth. “What was the closing price of this stock yesterday.” “When did this product launch.” The Sonar models are fast and the answer is one click away. My local stack takes 8 to 12 minutes per deep run, which is wrong for those queries.
Casual exploration where I do not yet know what I am looking for. Perplexity is excellent at producing a structured answer from a vague question. My local stack rewards a specific brief.
Mobile use. I do not yet have my local llama-server reachable from my phone, and I would not bother for a 22-cent query while walking.
For deep iterative research with primary sources, predictable cost, and zero quota anxiety, the local stack wins on every dimension that matters to me. For light queries, Perplexity Pro is still in my toolbox.
What I am watching for
Exa is currently the load-bearing dependency. If their pricing changes again, my 22 cents moves. The March 2026 simplification cut prices 20 percent on Deep search, which was helpful, but the direction is not guaranteed.
xAI deprecated the older Live Search API at the end of 2025. The Agent Tools API including x_search is the replacement path. The x_search piece of the stack depends on that path holding. If xAI pivots, I lose the X timeline layer until I rebuild it on the official X API at a higher cost per call.
GPT Researcher is open source and MIT-licensed. The framework risk is lower than the API risk. v3.4.4 shipped April 16 with active maintenance from Assaf and 220 contributors.
If you are running a cheaper or weirder research stack, drop the components below. I am especially interested in alternative retrievers (Brave Search, DuckDuckGo via DDGS), alternative local LLMs (DeepSeek V4, Gemma4), and what synthesis approaches you use without a Claude or ChatGPT subscription. The 22-cent number is not a floor.