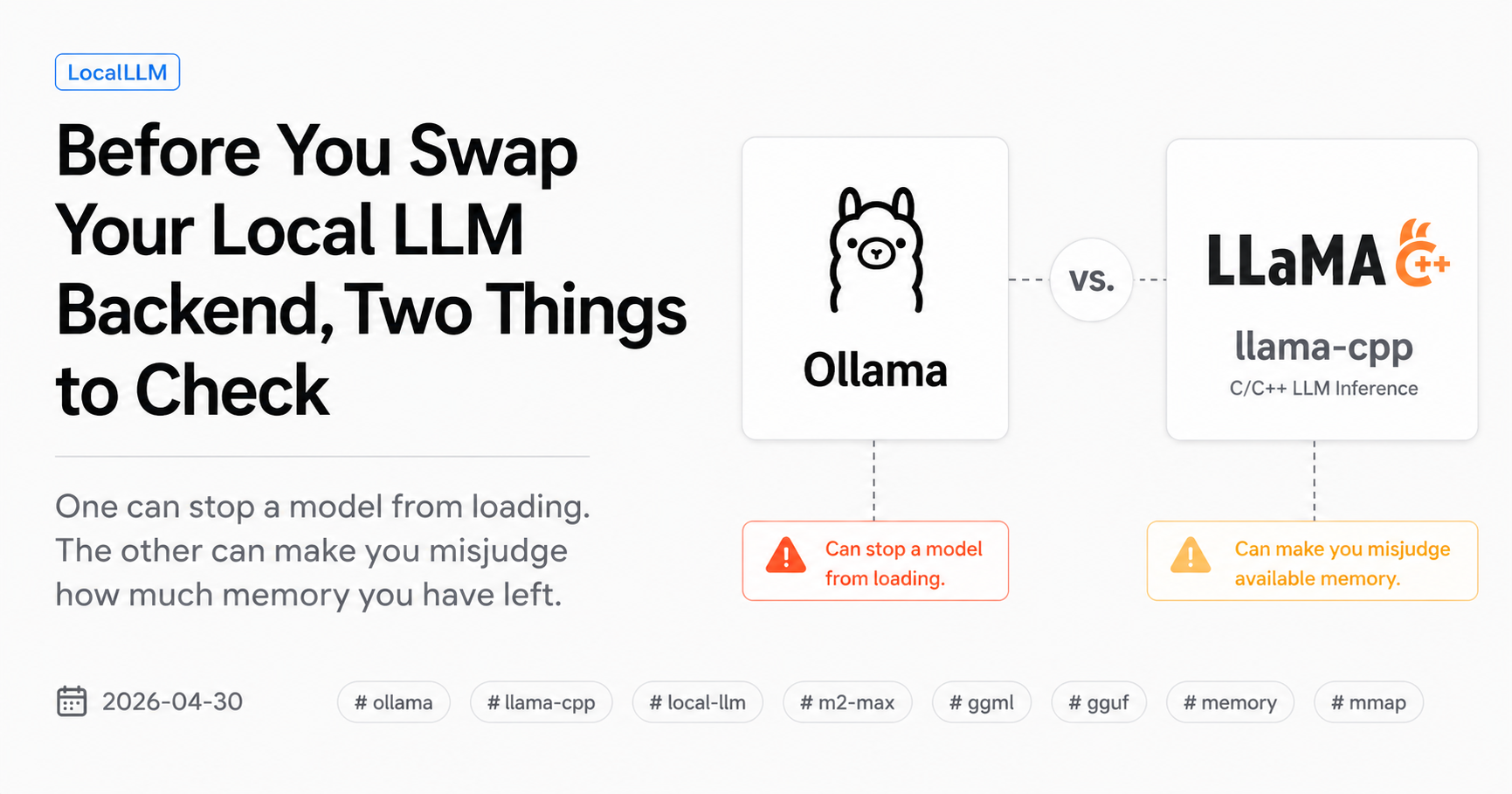
Ollama and llama.cpp: Three Structural Differences on the Same Model
For OpenAI-compatible local LLM serving I’d been using Ollama on a Mac Studio M2 Max 64 GB, with gemma4:26b as the default model and qwen3.5-nothink as an auxiliary. The community discussion around the two main local runtimes tends to frame it simply: “Ollama is a ggml fork, llama.cpp is faster.” A handful of residual errors on my stack and a recurring sense that something was slower than it should be made me want to test that framing on my own machine before swapping anything.
This post is what I found, with numbers, when I ran the same blob, the same prompt, and the same sampling parameters on both runtimes. It is not a benchmark roundup. It is not a recommendation to leave Ollama. It is a record of where the two runtimes actually differ in practice — three places, separable, reproducible.
What I wanted to test
Three patterns on the local stack that I wanted to attribute or rule out before swapping runtimes:
- Empty-looking tool call arguments on Gemma 4 — a prior notebook entry that flagged Gemma 4 tool calling as unstable on this stack. I had never actually measured its frequency.
- A 404 reference to
qwen3:32b-64kin a session dump. The model wasn’t pulled in Ollama yet; an upstream context-length cache had a stale entry pointing at it. - Subjective slowness on long-context turns — TTFT felt longer than I’d expect from a stack the community describes as the canonical local fast path.
The 404 is straightforward and was fixed by pulling the model. The other two were the falsification candidates.
The community signal
The April 2026 r/LocalLLaMA threads framed Ollama as ggml-derived but increasingly divergent. The most concrete public source is a quote attributed to Georgi Gerganov via a NixOS write-up in late 2025: Ollama “forked the ggml inference engine to rush out ‘day-1 support’” for GPT-OSS, producing an implementation that “was not only incompatible with standard GGUF files but also significantly slower and unoptimized.” Hugging Face discussion threads in March–April 2026 echoed this for Qwen3.5: “Currently no Qwen3.5 GGUF works in Ollama. Use llama.cpp compatible backends.”
This was the framing I went into the falsification with. The framing turned out to need significant correction.
Falsification design
The full design lives in drafts/impl_runtime_swap_falsification.md. The short version:
- Hypothesis (H): The Ollama runtime, not the model weights, is responsible for tool-call corruption, thinking-tag mishandling, and slower decode.
- Null (H0): Same weights produce equivalent behavior on both runtimes within noise.
- Control variables: feed the same Ollama blob to llama.cpp via
-m <blob>; match chat template via--jinja; pin sampling (temperature,top_p,top_k,seed); matchctx_size; both runtimes setparallel=1; warm both before measurement. - Tests:
- Test A — Tool-call JSON arguments, N=30
- Test B — Thinking-tag handling
- Test C — Decode throughput (t/s)
- Test D — Prefill TTFT
- Test E — Parallel tool calls, N=5
- Decision rule: 3+ tests support H ⇒ article as planned. 1–2 ⇒ narrowed scope. 0 ⇒ drop the article and record a negative result.
Format-level divergence: which blobs llama.cpp can load
Before any benchmark, I tried to load each Ollama blob directly into a current llama.cpp build (Homebrew formula 8940, post-tag b6869) using the blob path from ollama show <model> --modelfile.
| Blob (Ollama-distributed) | llama.cpp 8940 result |
|---|---|
gemma4:26b (Q4_K_M, Gemma 4 26B A4B MoE) |
Fails: done_getting_tensors: wrong number of tensors; expected 1014, got 658 |
qwen3:32b (Q4_K_M) |
Loads, chat template detected, server starts |
qwen3.5-nothink:latest (Q4_K_M) |
Fails: error loading model hyperparameters: key qwen35.rope.dimension_sections has wrong array length; expected 4, got 3 |
Two of the three fail. The third loads cleanly. The implication is that the format incompatibility is not blanket — it tracks specific newer architectures (Gemma 4 MoE, Qwen3.5) where Ollama appears to have shipped support ahead of upstream llama.cpp’s metadata expectations.
For the falsification I therefore split into two paths:
- Same-blob comparison (purely runtime-attributable): use
qwen3:32bon both runtimes. - Different-GGUF-source comparison (model-class-attributable): use Ollama’s
gemma4:26bblob on the Ollama side and the upstreamggml-org/gemma-4-26B-A4B-it-GGUFQ4_K_M on the llama.cpp side.
For the upstream HF GGUF I downloaded ggml-org/gemma-4-26B-A4B-it-GGUF/gemma-4-26B-A4B-it-Q4_K_M.gguf — 16.8 GB, SHA-256 88f4a13b…46abc. It loaded into llama.cpp 8940 in roughly four seconds.
Field-name divergence: same blob, different delta
The clearest finding from the run was something I wasn’t testing for directly. With Qwen3 thinking enabled by default on qwen3:32b, both runtimes were producing 1024 tokens of output but my harness was logging content=0. Inspecting raw streams resolved it:
# Ollama, qwen3:32b, default thinking, OpenAI-compatible streaming
data: {"choices":[{"delta":{"role":"assistant","content":"","reasoning":"Okay"}}],...}
# llama.cpp 8940, same blob, same prompt, same sampling
data: {"choices":[{"delta":{"reasoning_content":"Okay"}}],...}
Same blob. Same prompt. Same sampling parameters. The reasoning stream lands in different delta field names:
- Ollama:
delta.reasoning - llama.cpp:
delta.reasoning_content
The reasoning_content field name is the convention adopted by several reasoning-model APIs that have published their streaming format. llama.cpp follows that convention. Ollama uses its own reasoning. The two are not interchangeable for parsers.
The same pattern reproduces on Gemma 4 (different GGUF source on each side). On a 4-call sample with Gemma 4 thinking enabled and max_tokens=1024:
| Runtime | content avg | reasoning avg | reasoning_content avg |
|---|---|---|---|
| Ollama (gemma4:26b blob) | 770 chars | 2,128 chars | 0 |
| llama.cpp (HF GGUF) | 591 chars | 0 | 2,327 chars |
Two different model families, two different GGUF sources where applicable, and the field naming holds with the runtime, not with the model. This is a runtime-level design choice that would silently break any OpenAI-compatible client whose parser only knows about reasoning_content.
Runtime characteristics: prefill, decode, memory
Same blob, same prompt, same sampling, both runtimes set to parallel=1. All numbers from qwen3:32b Q4_K_M, ctx_size=40960. N=8 for the throughput regimes; warm runs only (first call discarded for KV-cache prefill).
Prefill TTFT — llama.cpp consistently 2–3x faster
| Regime (warm) | Ollama median TTFT | llama.cpp median TTFT | IQR overlap? |
|---|---|---|---|
| short prompt (~50 tok) | 318 ms | 107 ms | No |
| long prompt (~6,500 tok) | 352 ms | 113 ms | No |
IQR ranges do not overlap. The pattern repeats on Gemma 4 with even bigger margins (Ollama 265 → llama.cpp 50 ms on long warm).
Decode throughput — essentially equal on the same blob
| Regime | Ollama median t/s | llama.cpp median t/s |
|---|---|---|
| short | 14.2 | 13.8 |
| long | 12.8 | 12.9 |
This is the result that flatly contradicts the community framing of “Ollama is slower.” On the same Q4_K_M weights of qwen3:32b, on this M2 Max, Ollama’s decode is within 3% of llama.cpp’s. (On Gemma 4 with different GGUF sources, llama.cpp pulled ahead — but that comparison mixes runtime and quantization-packaging variables, and I am not going to attribute the gap.)
Memory footprint — Activity Monitor
I checked ps -axo rss first; Apple Silicon’s unified memory model makes those numbers misleading because Metal allocations don’t always show in process RSS. Activity Monitor’s “Memory” column showed numbers materially different from ps -axo rss for both runtimes, and the differences were consistent across repeated reads. I am using its values as the working signal here, with the caveat that the exact Metal-allocation accounting on Apple Silicon is not fully documented.
| Model (ctx) | Ollama (Activity Monitor) | llama-server (Activity Monitor) | Ratio |
|---|---|---|---|
| qwen3:32b dense, ctx=40960 | 28.95 GB | 13.47 GB | 2.15x |
| gemma4:26b A4B MoE, ctx=32768 | 19.01 GB | 3.29 GB | 5.78x |
The gap widens dramatically for the MoE model. The most likely explanation is mmap versus non-mmap: llama-server memory-maps the GGUF, so the OS treats model pages as page-cache that doesn’t count against process memory and can be evicted under pressure. Ollama’s runner appears to load the model into addressable Metal heap, where every byte of weights stays accounted to the process. For a 26B-total / 4B-active MoE the active weights are a small fraction of the file, so the file-mapped runtime looks much lighter even though both processes have the same logical model in memory.
This is an architectural difference, not a benchmark trick. It changes what “running three models at once on a 64 GB Mac” actually costs.
Tool calls and parallel tool calls — equally robust
| Test | Ollama | llama.cpp |
|---|---|---|
| Test A — single tool call JSON validity (N=30 each) | 30/30 valid (qwen3:32b), 32/32 (gemma4) | 30/30 valid (qwen3:32b), 30/30 (gemma4 HF) |
| Test E — three legitimate parallel tool calls (N=5 each) | 5/5 returned all 3 calls in one assistant turn | 5/5 returned all 3 calls in one assistant turn |
The original hypothesis — that Ollama corrupts tool-call arguments or fails on parallel tool calls — does not survive contact with the data. Both runtimes are equally correct on these axes for the models I tested.
What the data does and doesn’t say
What I am willing to say from these runs:
- Three structural divergences are real and reproducible: blob format compatibility (per-architecture),
deltafield naming, and memory accounting. - Prefill TTFT favors llama.cpp by 2–5x on warm runs, on the same blob.
- Decode throughput is within noise on the same blob.
- Tool-call correctness is equivalent on this hardware, for these models, in 2026-04.
What I am explicitly not claiming:
- “Ollama is slow.” The decode numbers don’t support it on the same blob.
- “Ollama is broken for tool calls.” Both runtimes returned 100% valid arguments and 3-of-3 parallel calls.
- “llama.cpp uses less memory in absolute terms.” It uses less non-mappable memory because of
mmap. The OS still holds the weights in page-cache. - “You should leave Ollama.” That is a configuration choice that depends on what you do with the runtime, not a one-size answer.
- Any of the above for multi-GPU rigs, NVIDIA hardware, Linux, or for any model family other than the three I tested.
The configuration change I actually made
The runtime swap is one line on the client side: any OpenAI-compatible client — the agent framework you happen to use, OpenWebUI, your own script — just changes its base_url.
- base_url: http://127.0.0.1:11434/v1 # Ollama default
+ base_url: http://127.0.0.1:8081/v1 # llama.cpp server
llama-server runs in the background, listening on port 8081, loading the model directly from the same Ollama blob path that Ollama itself reads:
llama-server \
-m ~/.ollama/models/blobs/sha256-<qwen3-32b-hash> \
--port 8081 --host 127.0.0.1 \
--ctx-size 40960 --parallel 1 --jinja \
--alias qwen3-32b
For Gemma 4 specifically, the Ollama blob is the one that doesn’t load in llama.cpp 8940, so the swap there means pointing llama-server at the upstream ggml-org/gemma-4-26B-A4B-it-GGUF Q4_K_M file — a different artifact, not the same bytes. The client-side base_url line is identical regardless.
The auxiliary qwen3.5-nothink:latest blob currently fails to load in llama.cpp 8940 because of the qwen35.rope.dimension_sections length-3 issue, unfixed in master as of late April 2026. Those calls keep going through Ollama until upstream merges a fix or I regenerate the GGUF locally.
What this post does not cover
If you are experiencing any of the following, the runtime swap above will not address it:
- NVIDIA / Linux setups. Different driver paths, different memory accounting, different tradeoffs. Not measured here.
- MLX / mlx-lm server. Apple’s own framework outperforms llama.cpp Metal on throughput in published 2026 benchmarks, but its OpenAI-compatible server story for tool calls is split between the official
mlx_lm.server(no tools) and the communitymlx-openai-server(tools, butparallel_tool_callsundocumented). I did not test it for this post. - Multi-model concurrent serving. llama.cpp’s mmap behavior is what makes this efficient; I tested only one model at a time per runtime.
- Quantizations other than Q4_K_M. Higher-bit quants will narrow the relative-cost picture.
Closing
The original premise — that the residual errors on the stack were caused by the runtime — is not supported by the data on this machine. What the falsification did surface is a more useful set of structural facts: Ollama’s distributed blobs are not interchangeable with upstream llama.cpp for newer architectures, the two runtimes serialize reasoning into different OpenAI-compatible field names, and the memory accounting differs by enough that it changes hardware planning for a multi-model setup.
The base_url swap took one line. The reason it took twelve hours to make the swap responsibly was the difference between “Ollama is the problem” and “here are the three places they actually diverge.”
My logs, my setup, my falsification. Verify on your own box.
Source material: Falsification runs on 2026-04-27, Mac Studio M2 Max 64 GB, Homebrew llama.cpp formula 8940 (post-tag b6869), Ollama latest stable. Raw test records and aggregated tables are kept locally.