LLM Cost Optimization: How to Reduce Your API Bills from $2,000 to $400/Month
LLM APIs are incredibly useful. They’re also incredibly expensive if you’re not paying attention.
A 5-person development team using GPT-4 and Claude across their daily workflows can easily hit $1,500–$2,000/month. Scale that to 20 developers and you’re looking at $6,000–$8,000/month — $72,000–$96,000 per year on API calls alone.
Most of that spend is often waste. Not because the tasks aren’t valuable, but because the wrong model is doing the work.
This article walks through 7 concrete techniques that can cut your LLM API bill by 60–80%. These aren’t hypothetical — they’re the same optimizations that took a real team’s spend from $2,000/month down to $400.
Key Takeaways
- Model routing is the biggest lever — sending simple tasks to cheaper or local models saves 50%+ with no quality loss.
- Prompt optimization compounds — shorter, clearer prompts reduce token count by 30–50% per request.
- Caching is free money — identical or near-identical requests happen more often than you think.
- Many teams don’t have a clear picture of what they’re spending on — the first step is always an audit.
- The techniques stack — applying 3–4 of these together is what gets you from $2,000 to $400.
Who This Is For
This guide is for:
- Engineering teams spending $200+/month on LLM APIs and suspecting they’re overpaying
- Engineering leads who need to justify AI costs to management — or reduce them
- Solo developers whose API bill is creeping higher each month
If you’re spending under $50/month, most of these optimizations won’t be worth your time. If you’re spending $200+, at least 3 of these will pay off immediately.
The Case Study: From $2,000 to $400
This example blends patterns from several real teams into a single, representative 5-person case. Numbers are rounded and simplified for clarity; savings from each technique are approximate and not strictly additive.
A 5-person development team used LLM APIs across their daily workflow:
| Use Case | Model | Monthly Tokens | Monthly Cost |
|---|---|---|---|
| Code completion (IDE) | GPT-4 Turbo | 4M | $120 |
| Code review | Claude 3 Opus | 3M | $270 |
| Documentation generation | GPT-4 Turbo | 2M | $60 |
| Summarization (meetings, Slack) | Claude Sonnet | 2M | $36 |
| Q&A and debugging | GPT-4 Turbo | 2M | $60 |
| Formatting and conversion | GPT-4o | 1M | $20 |
| Architecture and design | Claude Opus | 1M | $90 |
| Total | 15M | $656/month |
Wait — $656, not $2,000? That’s the optimized view. The original bill looked very different:
| Issue | Wasted Spend |
|---|---|
| Verbose prompts (2–3× longer than needed) | +$400 |
| No caching (repeated identical requests) | +$350 |
| GPT-4 used for formatting tasks | +$200 |
| Retries on failures (re-sending full prompts) | +$250 |
| Unused context in long conversations | +$150 |
| Actual original bill | ~$2,000/month |
The $2,000 was the bill before anyone looked at what was actually being sent. Let’s fix each source of waste.
Technique 1: Model Routing (Saves 40–60%)
This is the single highest-impact optimization. Most API spend goes to frontier models doing simple tasks. At the highest level, this is “use local and cheaper models wherever possible.” Later in Technique #4, we’ll apply the same idea within a single cloud provider.
The Fix
Route each task to the cheapest model that handles it at acceptable quality:
| Task | Before | After | Savings |
|---|---|---|---|
| Code completion | GPT-4 Turbo ($20/1M) | Local Llama 14B | 100% |
| Summarization | Claude Sonnet ($18/1M) | Local Llama 14B | 100% |
| Formatting | GPT-4o ($20/1M) | Local Llama 14B | 100% |
| Q&A | GPT-4 Turbo ($20/1M) | Local Llama 14B | 100% |
| Documentation | GPT-4 Turbo ($20/1M) | Local Llama 70B | 100% |
| Code review | Claude Opus ($90/1M) | Local Llama 70B | 100% |
| Architecture | Claude Opus ($90/1M) | Claude Opus | 0% |
After routing, only architecture and design tasks (the genuinely complex work) still hit the cloud.
Impact for this team: ~$500/month saved on the optimized $656 baseline (from $656 to ~$150 cloud-only).
For the full implementation, see Building Your Hybrid LLM Stack.
Technique 2: Prompt Optimization (Saves 20–40%)
Prompts are tokens. Tokens are money. Most prompts are 2–3× longer than they need to be.
Common Waste Patterns
Before (wasteful):
Can you please help me summarize the following meeting notes?
I'd like you to create a concise summary that captures the main
points discussed during the meeting. Please format the output as
bullet points, and make sure to include any action items that were
agreed upon. Here are the meeting notes:
[2,000 words of notes]
After (optimized):
Summarize as bullet points. Include action items.
[2,000 words of notes]
The instruction went from 52 tokens to 8 tokens. The notes are the same length either way. But across thousands of requests, those 44 tokens per call add up fast.
Rules of Thumb
- Cut the politeness. “Please,” “Can you help me,” “I’d like you to” — the model doesn’t care. Direct instructions produce identical output.
- Remove redundant context. Don’t explain what a summary is. Don’t describe the output format in paragraph form. Use a one-liner.
- Use system prompts for recurring instructions. Move static instructions to the system message — it’s sent once, not repeated in every user turn.
- Trim conversation history. For multi-turn chats, only include the last 3–5 relevant turns, not the full history.
Impact for this team: ~$300/month saved on the original $2,000 baseline (before routing).
Technique 3: Response Caching (Saves 15–25%)
Many LLM requests are identical or near-identical. Code completion, formatting, and Q&A tasks often repeat the same patterns.
Simple Cache Implementation
import hashlib
import json
import os
CACHE_DIR = ".llm_cache"
os.makedirs(CACHE_DIR, exist_ok=True)
def cache_key(model: str, messages: list) -> str:
content = json.dumps({"model": model, "messages": messages}, sort_keys=True)
return hashlib.sha256(content.encode()).hexdigest()
def get_cached(model: str, messages: list) -> str | None:
key = cache_key(model, messages)
path = os.path.join(CACHE_DIR, f"{key}.json")
if os.path.exists(path):
with open(path) as f:
return json.load(f)["content"]
return None
def set_cache(model: str, messages: list, content: str) -> None:
key = cache_key(model, messages)
path = os.path.join(CACHE_DIR, f"{key}.json")
with open(path, "w") as f:
json.dump({"content": content}, f)
Wrap your API calls with cache checks. For deterministic tasks (formatting, conversion, translation), set temperature to 0 and cache aggressively.
What to Cache
| Task | Cacheable? | Reason |
|---|---|---|
| Formatting/conversion | Yes — always | Same input = same output |
| Translation | Yes — usually | Deterministic at temp 0 |
| Summarization | Yes — with same input | Same document = same summary |
| Code completion | Partially | Same prefix often = same completion |
| Creative writing | No | You want variation |
| Debugging/Q&A | Partially | Same question = same answer, but context varies |
Impact for this team: ~$350/month saved on the original $2,000 baseline (repeated requests hitting the API unnecessarily).
Technique 4: Model Downgrades for Non-Critical Tasks (Saves 10–20%)
Even within cloud APIs, not every task needs the most expensive model.
| Task | Expensive Choice | Cheaper Choice | Quality Difference |
|---|---|---|---|
| Simple Q&A | GPT-4 Turbo ($20/1M) | GPT-4o Mini ($0.60/1M) | Negligible |
| Formatting | Claude Opus ($90/1M) | Claude Haiku ($1/1M) | None |
| First-draft generation | GPT-4 ($30/1M output) | GPT-3.5 Turbo ($2/1M) | Slight |
For tasks that stay in the cloud (because local isn’t an option or you don’t have the hardware), downgrading from Opus to Haiku or from GPT-4 to GPT-4o Mini can cut costs by 90% on those specific calls — with minimal quality impact.
Impact for this team: ~$100/month saved on the remaining cloud-only tasks.
Technique 5: Retry and Error Optimization (Saves 5–15%)
Failed API calls are pure waste. You pay for the tokens sent, even if the response is useless.
Common Retry Waste
- Timeout → full retry — if a request times out at 90%, you pay for 90% of the tokens and then pay again for the full retry
- Rate limit → immediate retry storm — retrying instantly when rate-limited wastes requests and burns through quota
- Bad output → same prompt retry — if the model gave bad output, sending the exact same prompt again usually gives the same bad output
Fixes
import time
from openai import RateLimitError, APITimeoutError
def call_with_smart_retry(client, model, messages, max_retries=3):
for attempt in range(max_retries):
try:
return client.chat.completions.create(
model=model,
messages=messages,
timeout=30,
)
except RateLimitError:
wait = 2 ** attempt # exponential backoff: 1s, 2s, 4s
time.sleep(wait)
except APITimeoutError:
# Don't retry the same long prompt — shorten or switch models
if attempt == 0:
messages = _truncate_context(messages)
else:
raise
raise Exception("Max retries exceeded")
- Exponential backoff on rate limits — don’t hammer the API
- Truncate context on timeout — if it timed out, the prompt was probably too long
- Don’t retry identical prompts for quality — modify the prompt or switch models instead
Impact for this team: ~$250/month saved on the original $2,000 baseline (retries were a significant cost that nobody was tracking).
Technique 6: Context Window Management (Saves 5–10%)
Long conversations accumulate tokens fast. A 20-turn conversation with GPT-4 can hit 10,000+ tokens just in context — before the model generates a single output token.
Fixes
- Sliding window: Keep only the last N turns (3–5 is often sufficient)
- Summarize old context: Replace turns 1–15 with a one-paragraph summary, keep turns 16–20 verbatim
- Reset aggressively: For new topics in the same session, start a fresh conversation instead of continuing
def trim_conversation(messages: list, max_turns: int = 5) -> list:
system = [m for m in messages if m["role"] == "system"]
conversation = [m for m in messages if m["role"] != "system"]
if len(conversation) > max_turns * 2: # user + assistant = 2 messages per turn
conversation = conversation[-(max_turns * 2):]
return system + conversation
Impact for this team: ~$150/month saved on the original $2,000 baseline (long debugging conversations were the primary culprit).
Technique 7: Usage Auditing and Monitoring (Enables Everything Else)
You can’t optimize what you don’t measure. Many teams don’t have a clear picture of which tasks, which team members, or which features drive their API spend.
What to Track
| Metric | Why |
|---|---|
| Tokens per request (input + output) | Identifies verbose prompts |
| Requests per task type | Shows where volume is highest |
| Cost per task type | Shows where spend is highest (not always the same as volume) |
| Model per request | Reveals if expensive models are used for simple tasks |
| Cache hit rate | Measures caching effectiveness |
| Retry rate | Reveals wasted spend on failures |
| Latency per tier | Ensures local models are fast enough |
Minimal Logging
If you’ve built the hybrid LLM stack, you already have JSONL logging. If not, add this to every API call:
import json
from datetime import datetime
def log_usage(model: str, task_type: str, tokens: int, cost: float):
with open("llm_usage.jsonl", "a") as f:
f.write(json.dumps({
"timestamp": datetime.now().isoformat(),
"model": model,
"task_type": task_type,
"tokens": tokens,
"cost": cost,
}) + "\n")
Review weekly. The patterns will surprise you — the biggest cost driver is rarely the task you’d expect.
Combined Impact: The Full Optimization
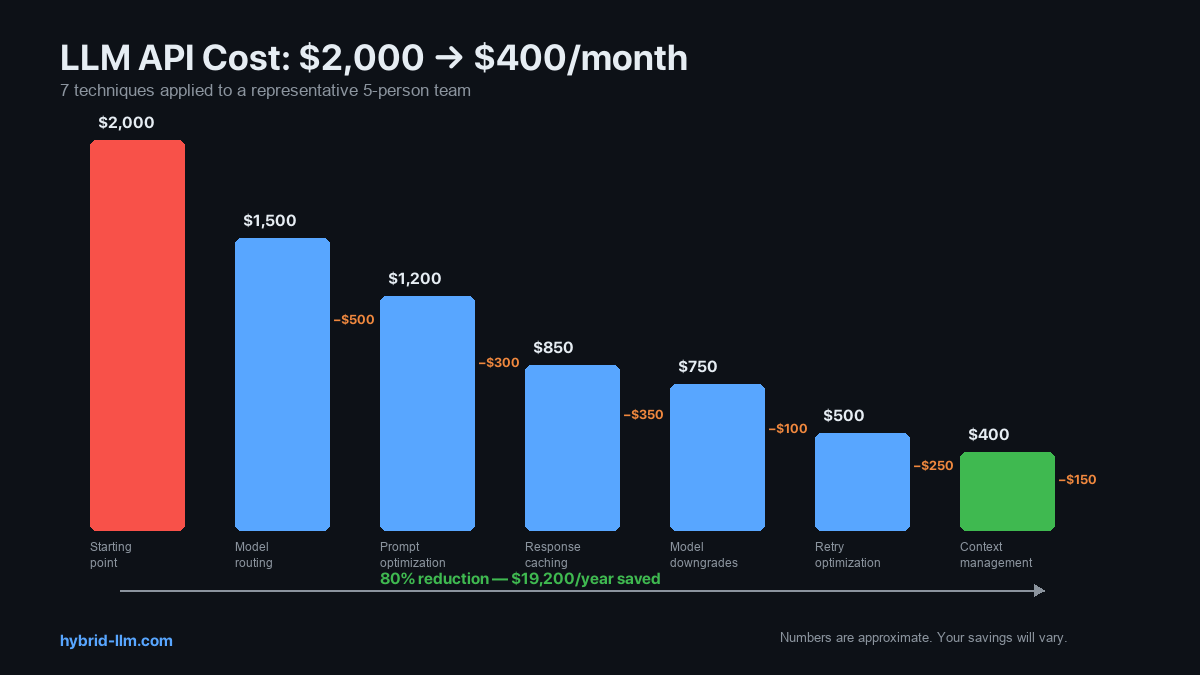
Here’s how the 7 techniques stacked for our case study team:
| Technique | Monthly Savings | Cumulative Bill |
|---|---|---|
| Starting point | — | $2,000 |
| 1. Model routing | -$500 | $1,500 |
| 2. Prompt optimization | -$300 | $1,200 |
| 3. Response caching | -$350 | $850 |
| 4. Model downgrades | -$100 | $750 |
| 5. Retry optimization | -$250 | $500 |
| 6. Context management | -$150 | $350 |
| 7. Usage auditing | Essential — teams that skip this usually stall after Technique #1 | — |
| Final bill | ~$350–400/month |
That’s an 80% reduction — from $2,000 to $400. Annual savings: $19,200.
These numbers are from one representative workload. Your results will vary depending on your task mix, team size, and current spend. Some teams will only see 30–50% savings; others may see more than 80% if they started from a very inefficient baseline. But the techniques themselves are universal — most teams that apply 3+ of these see at least a 40% reduction.
Prioritization: Where to Start
Not every technique is worth implementing immediately. Here’s the priority order based on effort vs. impact:
| Priority | Technique | Effort | Impact | Start If… |
|---|---|---|---|---|
| 1 | Usage auditing (#7) | 30 min | Enables all others | You don’t know your cost breakdown |
| 2 | Model routing (#1) | 2 hours | 40–60% | You’re sending everything to GPT-4 |
| 3 | Prompt optimization (#2) | 1 hour | 20–40% | Your prompts are verbose |
| 4 | Caching (#3) | 1 hour | 15–25% | You have repetitive tasks |
| 5 | Model downgrades (#4) | 30 min | 10–20% | You’re using Opus/GPT-4 for simple tasks |
| 6 | Retry optimization (#5) | 1 hour | 5–15% | Your error rate is >5% |
| 7 | Context management (#6) | 1 hour | 5–10% | You have long chat sessions |
Start with #7 (audit), then #1 (routing). Those two alone typically cut spend by 50%.
What’s Next
Implement these optimizations with the tools from the HybridLLM.dev series:
- Building Your Hybrid LLM Stack — The full router implementation (Technique #1)
- Hybrid LLM Architecture — The concept behind tiered routing
- GPT-4 vs Local Llama 3.3 — Quality evidence for safe model downgrades
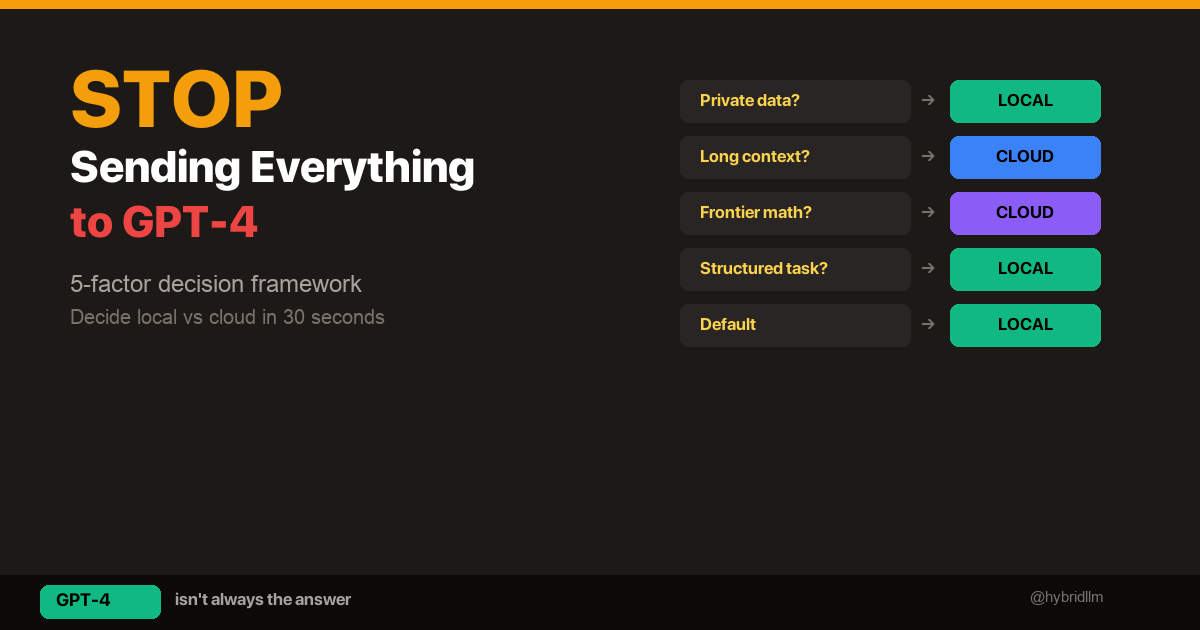
- Local vs Cloud Decision Framework — Decide which tasks can go local
- Best Local LLM Models for Mac — Choose the right local model for your hardware
Follow @hybridllm for cost optimization case studies and techniques as pricing evolves.