GPT-4 vs Local Llama 3.3: Quality, Speed, and Cost Comparison 2026
GPT-4 is the gold standard for LLM quality. Llama 3.3 is the best open-source model you can run on your own hardware. One costs money. The other costs nothing.
But “free” means nothing if the output isn’t good enough.
This article puts them head-to-head across the tasks developers actually care about — code generation, summarization, reasoning, and more. No synthetic benchmarks. No cherry-picked examples. Just an honest comparison to help you decide where each model earns its place in your workflow.
Key Takeaways
- Llama 3.3 14B comes very close to GPT-4 on simple tasks — summarization, formatting, translation, and basic code generation are hard to tell apart in practice.
- GPT-4 pulls ahead on complex reasoning — multi-step logic, long-context analysis, and nuanced instruction-following show a real gap.
- Llama 3.3 70B narrows the gap significantly — on most tasks, 70B output is within striking distance of GPT-4.
- Speed depends on your setup — GPT-4 has higher peak throughput, but local models are consistent and never rate-limited.
- Cost is not close — a team spending $600/month on GPT-4 can route 70%+ of those tasks to Llama locally for $0.
Who This Comparison Is For
This is for developers who:
- Are currently paying for GPT-4 (or considering it) and want to know what they’d lose by switching some tasks to local
- Have a Mac with 16GB+ RAM or a PC with a decent GPU and want to understand the practical quality gap
- Need hard data — not opinions — to justify a local-first or hybrid approach to their team
The Models
| GPT-4 Turbo | Llama 3.3 14B (Local) | Llama 3.3 70B (Local) | |
|---|---|---|---|
| Parameters | ~1–2T (MoE, unofficial estimates) | 14B | 70B |
| Context window | 128k tokens | 4k–8k practical | 4k–8k practical |
| Cost (per 1M tokens) | $10 input / $30 output | $0 | $0 |
| Where it runs | OpenAI servers | Your machine | Your machine (64GB+ RAM) |
| Speed | 30–80 tok/s | 13–22 tok/s | 8–18 tok/s |
| Data privacy | Sent to OpenAI | Stays local | Stays local |
Parameter counts for GPT-4 are unconfirmed estimates. Llama speeds are Apple Silicon benchmarks with Q4_K_M quantization; expect ±10–15% variance.
Head-to-Head: Task-by-Task Comparison
I ran each model through the same set of developer tasks (5–10 prompts per category) and rated output quality on a 5-point scale. Ratings are my own judgment and should be read as directional, not definitive.
Code Generation
Task: “Write a Python function that takes a list of file paths, reads each file, and returns a dictionary mapping filenames to word counts. Handle missing files gracefully.”
| Criteria | GPT-4 Turbo | Llama 14B | Llama 70B |
|---|---|---|---|
| Correctness | ★★★★★ | ★★★★☆ | ★★★★★ |
| Error handling | ★★★★★ | ★★★★☆ | ★★★★★ |
| Code style | ★★★★★ | ★★★★☆ | ★★★★★ |
| Edge cases | ★★★★★ | ★★★☆☆ | ★★★★☆ |
Verdict: For straightforward code generation, all three produce working code. GPT-4 and 70B add more edge case handling (empty files, encoding issues) without being asked. 14B produces clean, correct code but needs more specific prompting for edge cases.
Code Review
Task: Review a 120-line Python module with 3 intentional bugs (off-by-one error, unclosed file handle, race condition).
| Criteria | GPT-4 Turbo | Llama 14B | Llama 70B |
|---|---|---|---|
| Bugs found (out of 3) | 3/3 | 1/3 | 3/3 |
| False positives | 0 | 1 | 0 |
| Explanation quality | ★★★★★ | ★★★☆☆ | ★★★★☆ |
| Fix suggestions | ★★★★★ | ★★★☆☆ | ★★★★★ |
Verdict: This is where the parameter gap shows. 14B caught the obvious off-by-one but missed the race condition entirely. 70B found all three and provided solid fix suggestions. GPT-4’s explanations were slightly more detailed, but 70B’s were actionable.
Summarization
Task: Summarize a 2,000-word technical blog post into 3 bullet points.
| Criteria | GPT-4 Turbo | Llama 14B | Llama 70B |
|---|---|---|---|
| Accuracy | ★★★★★ | ★★★★★ | ★★★★★ |
| Conciseness | ★★★★★ | ★★★★☆ | ★★★★★ |
| Key point selection | ★★★★★ | ★★★★☆ | ★★★★★ |
Verdict: Very close. If you showed me the three outputs unlabeled, I’d struggle to tell which came from GPT-4. For standard summarization tasks, 14B models are more than adequate.
Multi-Step Reasoning
Task: “A company has 3 warehouses. Warehouse A is 20 miles from the customer, B is 35 miles, C is 15 miles. A has 80% of the inventory, B has 15%, C has 5%. Shipping costs $2/mile. If the customer orders 100 units and we want to minimize cost while fulfilling the order from the fewest warehouses, what’s the optimal strategy?”
| Criteria | GPT-4 Turbo | Llama 14B | Llama 70B |
|---|---|---|---|
| Correct answer | ★★★★★ | ★★★☆☆ | ★★★★☆ |
| Reasoning chain | ★★★★★ | ★★☆☆☆ | ★★★★☆ |
| Handles constraints | ★★★★★ | ★★☆☆☆ | ★★★★☆ |
Verdict: The clearest gap. 14B struggled to hold all constraints simultaneously — it optimized for distance but forgot the “fewest warehouses” constraint. 70B got the right answer but with a slightly less elegant reasoning chain. GPT-4 nailed it cleanly on the first attempt.
Translation
Task: Translate a technical paragraph from English to Japanese, preserving technical terminology.
| Criteria | GPT-4 Turbo | Llama 14B | Llama 70B |
|---|---|---|---|
| Accuracy | ★★★★★ | ★★★★☆ | ★★★★★ |
| Technical terms | ★★★★★ | ★★★★☆ | ★★★★★ |
| Natural flow | ★★★★★ | ★★★☆☆ | ★★★★☆ |
Verdict: 14B produces usable translations but occasionally sounds slightly mechanical. 70B is nearly indistinguishable from GPT-4 for major language pairs. For minor languages, GPT-4 still has an edge from broader training data.
Data Formatting
Task: Convert a messy CSV with inconsistent date formats, mixed delimiters, and empty fields into clean JSON.
| Criteria | GPT-4 Turbo | Llama 14B | Llama 70B |
|---|---|---|---|
| Correctness | ★★★★★ | ★★★★★ | ★★★★★ |
| Edge case handling | ★★★★★ | ★★★★☆ | ★★★★★ |
| Speed of response | Fast | Faster (local) | Fast |
Verdict: All three handle formatting tasks well. This is exactly the kind of task that doesn’t need frontier intelligence — and where paying GPT-4 per-token rates is pure waste.
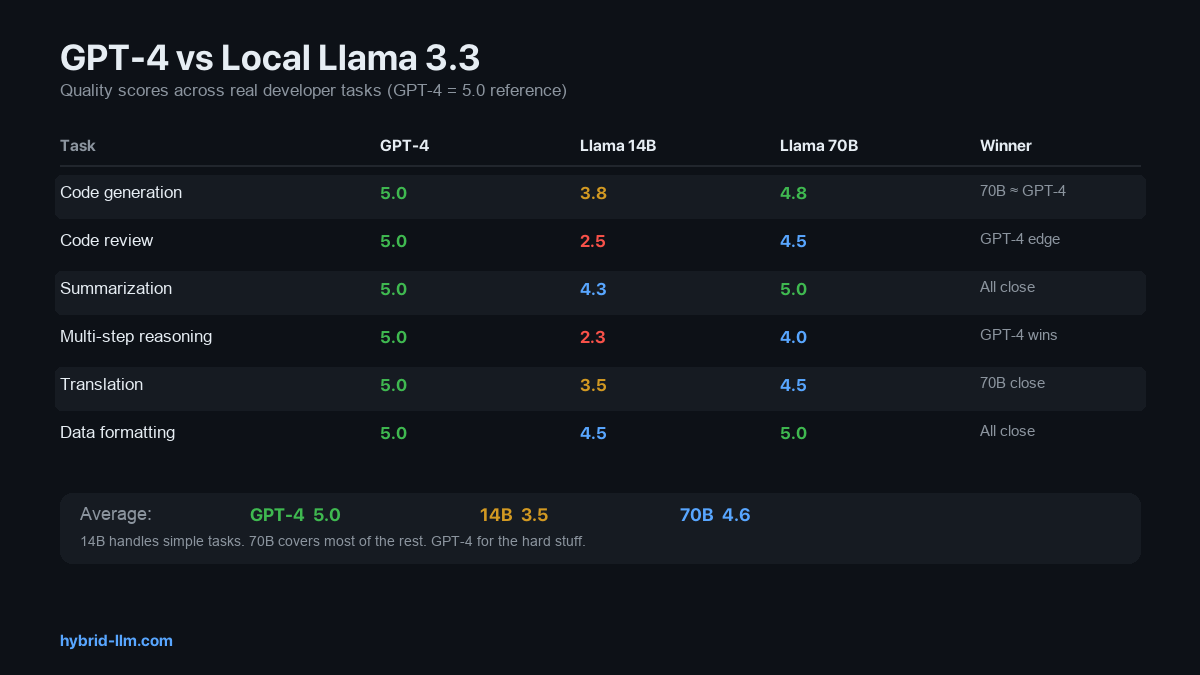
Summary Scorecard
| Task | GPT-4 Turbo | Llama 14B | Llama 70B |
|---|---|---|---|
| Code generation | 5.0 | 3.8 | 4.8 |
| Code review | 5.0 | 2.5 | 4.5 |
| Summarization | 5.0 | 4.3 | 5.0 |
| Multi-step reasoning | 5.0 | 2.3 | 4.0 |
| Translation | 5.0 | 3.5 | 4.5 |
| Data formatting | 5.0 | 4.5 | 5.0 |
| Average | 5.0 | 3.5 | 4.6 |
GPT-4 is the quality ceiling — by definition, it scores 5.0 as the reference point. The question is whether the gap justifies the cost.
Llama 14B at 3.5/5.0: Good enough for simple tasks (summarization, formatting, basic code). Falls short on reasoning and code review.
Llama 70B at 4.6/5.0: Genuinely close to GPT-4 on most tasks. The gap only shows on complex multi-step reasoning and edge case handling.
If you only remember one thing from this article: use Llama 14B for simple tasks, Llama 70B for medium tasks, and GPT-4 for the hard stuff. The detailed breakdown follows — but that’s the punchline.
Speed Comparison
Speed matters differently depending on the use case.
| Metric | GPT-4 Turbo | Llama 14B (M3 Pro 18GB) | Llama 70B (M2 Ultra 128GB) |
|---|---|---|---|
| First token | 200ms–1s | 100–300ms | 500ms–2s |
| Generation speed | 30–80 tok/s | 15–22 tok/s | 13–18 tok/s |
| 500-word response time | 3–8s | 10–15s | 15–25s |
| Rate limited? | Yes (per tier) | Never | Never |
| Available at 3 AM? | Usually | Always | Always |
Cloud latency varies by region, provider load, and your API tier; these ranges assume normal conditions.
For interactive use: GPT-4’s higher throughput makes it feel snappier for longer outputs. The 14B local model is fast enough for short responses but noticeably slower for long-form generation.
For batch processing: Local wins outright. No rate limits, no queue times, no surprise throttling. You can process thousands of documents overnight at full speed. With batching, local throughput for bulk jobs can match or exceed GPT-4’s effective rate when you factor in queue waits and rate-limit pauses.
Cost Comparison
This is where the math gets interesting.
Monthly Cost by Volume
| Monthly Tokens | GPT-4 Turbo | Llama 14B | Llama 70B | Hybrid (70% local) |
|---|---|---|---|---|
| 1M | $20 | $0 | $0 | $6 |
| 5M | $100 | $0 | $0 | $30 |
| 15M | $300 | $0 | $0 | $90 |
| 50M | $1,000 | $0 | $0 | $300 |
Hybrid column assumes 70% of tokens routed to local (Tier 1 tasks), 30% to GPT-4 (Tier 3 tasks). This split assumes quality is acceptable on local for that 70% — your ratio will depend on your task mix.
Annual Cost for a Team of 5
| Approach | Monthly | Annual |
|---|---|---|
| GPT-4 for everything | $600 | $7,200 |
| Hybrid (70% local) | $180 | $2,160 |
| Savings | $420 | $5,040 |
The savings scale linearly with team size. A team of 20 saves $20,000+/year.
Hardware Cost (One-Time)
If you don’t already own the hardware:
| Setup | Cost | What You Get |
|---|---|---|
| MacBook Air M3 16GB | $1,200 | Tier 1 (14B) |
| MacBook Pro M3 Pro 36GB | $2,400 | Tier 1 + solid Tier 2 (32B) |
| Mac Studio M2 Ultra 64GB | $4,000 | Full Tier 1 + Tier 2 (70B) |
A team already using Macs has zero additional hardware cost. The ROI is immediate.
When GPT-4 Is Worth the Money
Despite the cost gap, GPT-4 earns its price in specific scenarios:
- Complex code review where bugs have real consequences — GPT-4’s edge case coverage is measurably better than 14B, and slightly better than 70B
- Multi-step reasoning with 3+ constraints — the gap between 70B and GPT-4 is real here
- Very long context (16k+ tokens) — GPT-4 handles 128k tokens natively; local models degrade past 8k
- Novel problem-solving — tasks with no clear pattern for the model to follow
- When speed of generation matters for UX — GPT-4’s throughput advantage makes a difference for user-facing features
For everything else, the local option saves money without sacrificing meaningful quality.
The Hybrid Verdict
The data points to the same conclusion across every comparison:
| Task Complexity | Best Option | Why |
|---|---|---|
| Simple (summarize, format, translate) | Llama 14B local | Quality is equal. Cost is $0. |
| Medium (code gen, code review, writing) | Llama 70B local | Quality is 90%+ of GPT-4. Cost is $0. |
| Hard (complex reasoning, long context) | GPT-4 cloud | Quality gap is real and worth paying for. |
Don’t choose one or the other. Use both.
Route the 70% of tasks that are simple to local. Route the 15% that are medium to local 70B. Reserve GPT-4 for the 15% that genuinely need it.
That’s the hybrid approach, and it’s why this site is called HybridLLM.dev.
What’s Next
Set up your local models and start comparing:
- LM Studio Setup Guide 2026 — Get Llama 3.3 running in 5 minutes
- Best Local LLM Models for Mac — Find the right model for your hardware
- Running Llama 3.3 70B Locally — Set up the 70B model
- Hybrid LLM Architecture — Build the router that makes this work
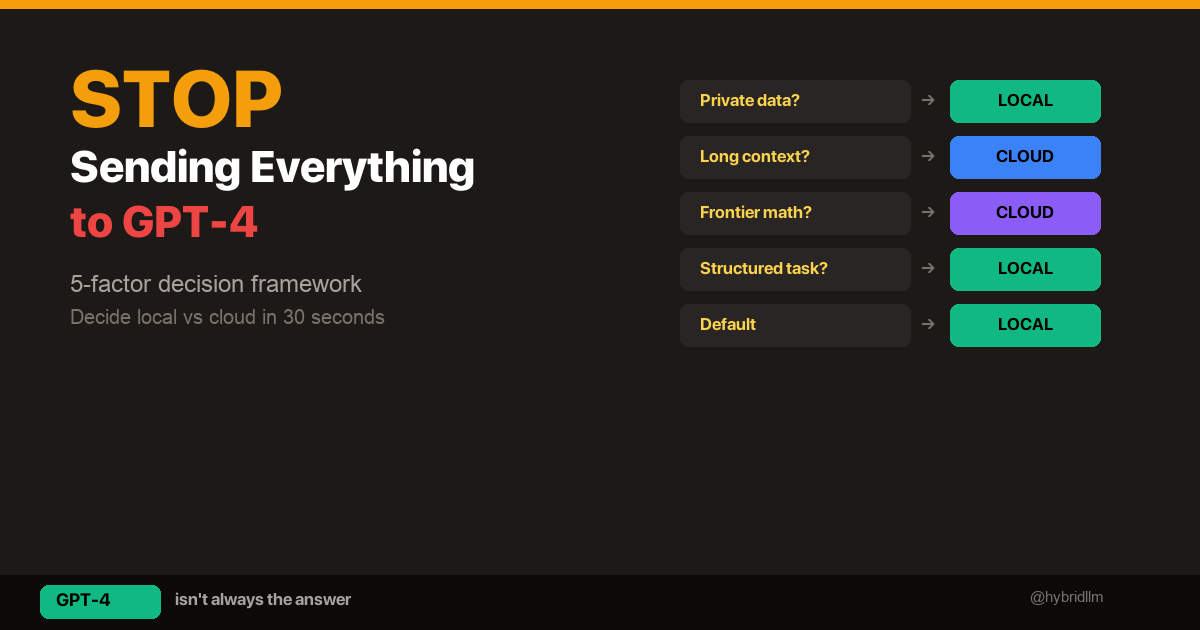
- Local vs Cloud Decision Framework — The 30-second checklist for every new task
Follow @hybridllm for model comparison updates as new releases drop.